
How does one add floating point numbers? Subtract them? To answer this question, first examine the way you would add the following decimal numbers: 34.568 + 0.0072. The first thing to do is to write the numbers in a column, aligning the decimal point, then perform what amounts to integer addition, keeping the decimal point in its fixed position.
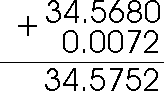
What about for numbers written in an exponential form? For example, how would you add 4.56 x 103 to 53.21 x 10-1? Would this work in the same way?
Well, not quite. Remember that an exponent means that the radix point actually belongs in a different position than in which it is shown. For example, in 4.56 x 103 the exponent '3' means the decimal point really belongs three places to the right from where it is, so that this number (when written without exponents) is 4,560. So, aligning the decimal points won't work unless the exponents are also the same.
FIRST RULE OF FLOATING-POINT ADDITION: Determine which exponent is the smaller exponent. Rewrite that number using the larger exponent, so that the two exponents are now the same.
In our example, the second number has the smaller exponent (-1). We need to rewrite that number using an exponent of 3. This means moving the decimal point 4 places to the left.
53.21 x 10-1 = 0.005321 x 103
So now our addition looks like this:
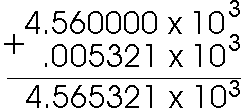
Binary floating point addition works the same way. Suppose we needed to add the following binary floating point numbers:
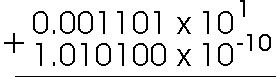
Rememeber that all numbers are shown in binary, so the first number is raised to the 1st power. The second number is raised to -2. We need to promot the second number from exponent -2 to exponent 1 by moving the binary point left 3 places, then perform the addition.
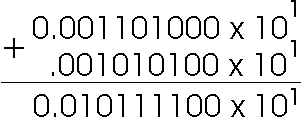
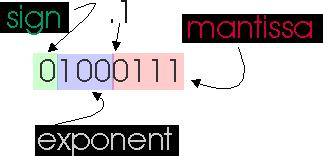
When working with floating point numbers that have been stored in computer memory using formats such as IEEE 754, must take a result such as the one above normalize it for storage. Suppose we were going to store the above result in our example floating-point format of 8 bits (1 sign bit, 3 bits for biased exponent, and 4 bits for mantissa). First we will have to normalize the answer to normal exponential form.
![]()
Next, since we can only store 5 bits of the mantissa (remember, the .1 is implied) we will have to truncate any other bits. The bits in the highlighted box below are the ones we must truncate.

Now, for the exponent. Since we have a 3-bit (t=3) field for storing the exponent, the bias will be 2t-1=22=4. So, store exponent 0 we must add 4 to it, and store that value. 0+4=4. So the biased exponent (or characteristic) is 100. The 8 bit number we store will be:
Consider the two floating-point numbers stored in our example 8-bit format: 10010111 and 11101101. How do we add them? First, let's write them in normalized exponential form.
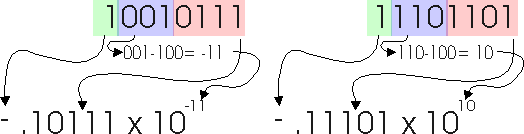
The first number has the smaller exponent (-3) which we must promote to the larger exponent (2) by adding 5 0's to the left. So now we can compute the result:
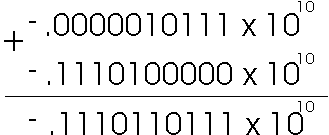
Now we normalize and truncate the result to a 5-bit mantissa to get:
-.11101 x 1010
This number is the same as the second number! What happened to the first number? It turns out that the second number was so small that, when promoted to the larger exponent, the significant digits of the smaller number could not longer be represented. You can see that they were truncated. It is as if we added zero to the second number. This illustrates the kinds of error that can occur when performing floating-point operations.
SECOND RULE OF FLOATING-POINT ADDITION: Be careful when adding numbers with very different exponents since significant error can be introduced.
Because floating-point representation is an approximate one, errors are always going to occur. The trick is to minimize the effect errors have. What can you do in a situation such as the one above? The best answer is to use a representation which offers more precision. Most programming languages offer at least two kinds of floating-point representations. For example, the C programming language offers the float type, which is single precision, and the double type, which is double precision. The double type should be used when you experience precision problems with single precision. However, keep in mind that the double type requires not only twice as much storage space (bits), but also takes longer to compute. The IEEE 754 specification provides both a single-precision format (which we have seen) and a double precision format.
Other problems that can occur when performing floating-point addition are overflow and underflow.
Overflow occurs when the result has an exponent that is too large in the positive direction, meaning that the magnitude of the entire number (whether the number is postive or negative) is too far away from zero to be represented. Let x and -x represent the largest number (postive and negative) we can represent with a storage format. Overflow occurs if we try to store a number n such that n < -x or x < n.
Underflow occurs when the result has an exponent that is too large in the negative direction, meaning that magnitude of the entire number (whether the number is positive or negative) lies between zero and the smallest fraction we can actually represent. Let x and -x represent the smallest number (positive and negative) we can represent with a storage format. In other words, the only we can represent which lies between them is zero. Underflow occurs if we try to store any number n such that -x < n < 0 or 0 < n < x.
Next Module: Logic and Truth Tables, Boolean
Algebra
Previous
Section: Floating-point Representation
Return to
Module Index