

Syntax
 Syntax is what a program looks like. More formally,
which strings of characters form a legal program?
Syntax is what a program looks like. More formally,
which strings of characters form a legal program?
These notes cover Chapter 2, and mentions a few things
which your authors cover in Chapter 3.
Chapter 3 goes into more detail than we need for this class; you
are responsible for Chapter 2, and whatever else is mentioned here.
- Syntax issues.
- Character set.
- Blanks
- Usually discarded except in string literals.
- Separate parts.
- Python uses indents for grouping.
- Fixed v. free format.
- Early languages: one statement per card or line.
- Position on the line matters.
- Later: ignore lines and white space, terminate with semicolon.
- Retro trend: to lines: Python, Ruby.
- Expressing structure.
- Context-Free Grammars / Backus-Naur Form
- Substitution rules.
| binaryDigit | → | 0 | 1 |
| unsignedBinaryNumber | → | binaryDigit | binaryDigit unsignedBinaryNumber |
| binaryNumber | → | sign unsignedBinaryNumber |
| sign | → | + | − |
- A grammar has:
- Set of productions P
Each of listed rules is a production.
- Set of terminal symbols T
Symbols like 0 that aren't replaced.
- Set of non-terminal symbols N
Symbols like binaryNumber that are replaced.
- One non-terminal is the desginated the start symbol.
- A series of replacements to a string of all terminals
is a derivation.
- The set of all the strings which can be derived from a
grammar is the language of the grammar.
- BNF notation
| ⟨binaryDigit⟩ | ::= | 0 | 1 |
| ⟨unsignedBinaryNumber⟩ | ::= | ⟨binaryDigit⟩ | ⟨binaryDigit⟩ ⟨unsignedBinaryNumber⟩ |
| ⟨binaryNumber⟩ | ::= | ⟨sign⟩ ⟨unsignedBinaryNumber⟩ |
| ⟨sign⟩ | ::= | + | − |
- Extended notation
| binaryDigit | → | 0 | 1 |
| unsignedBinaryNumber | → | binaryDigit { binaryDigit } |
| binaryNumber | → | ( + | − ) unsignedBinaryNumber |
- Imposes structure.
- Parse trees.
| expr | → | expr + term | term |
| term | → | term * prod | prod |
| prod | → | id | const | ( expr ) |
| id | → | a | b | c |
| const | → | 1 | 2 | 3 |
- Ambiguity.
| expr | → | expr + expr | expr * expr | ( expr ) | id | const |
| id | → | a | b | c |
| const | → | 1 | 2 | 3 |
- Dangling else problem.
| stmt | → | id := expr |
| stmt | → | if expr then stmt |
| stmt | → | if expr then stmt else stmt |
- Left-most and right-most derivations.
- ECFG for Tucker and Noonan's Clite Language
- Tokens
- Grammar has to end somewhere.
- Can go to characters; usually end with “tokens”.
- Identifiers.
- Keywords.
- Operators and punctuation.
- Literals (constants).
- Examples Grammars
- Pascal (offsite)
- Plain C
- Java (offsite)
- Abstract syntax.
- Throw away the structural tokens: keywords, punctuation.
- Collapse single symbol replacements, like expr → term.
- Remainder describes the computation.
| expr | = | binary | varref | const |
| binary | = | operator op; expr left, right; |
| operator | = | + | * |
| varref | = | String id |
| const | = | Integer val |
- Abstract Syntax for for Tucker and Noonan's Clite Language
- Tokens: Terminals in a language grammar.
- Language CFG terminals are not individual characters.
- Terminate with “tokens”: identifiers, constants (various types),
operators and punctuation.
- Regular expressions describe tokens.
- Characters represent themselves.
- Operators * + and |.
- Character sets.
- Examples (Unix notation)
- Identifier (no underscores): [A-Za-z][A-Za-z0-9]*
- Optionally-signed integer: [+-]?[0-9]+
- Floating-point (no exponential notation):
[0-9]+\.[0-9]*|\.[0-9]+
- Compiling.
- Compiling phases.
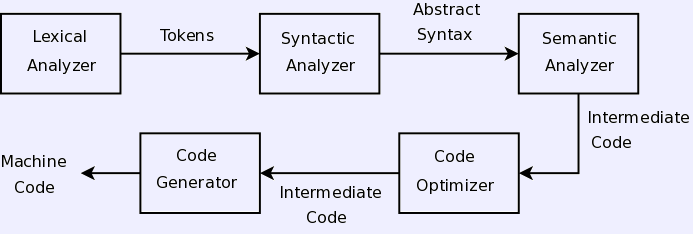
- Scanning.
- Finite automata implement regular expressions.
- Scanner reports a stream of tokens.
- Scanner discards white space and comments.
- Greedy matching.
- Parsing.
- Produce the a parse tree from the token stream.
- Recursive descent (top-down).
- Directly-implemented.
- Table-driven.
- Bottom-up.
Problems: 2.5, 2.6, 2.7, 2.8 (with Term × Factor), 3.3, 3.10.
Write a CFG to describe Tom's Lisp (there's not much to it).
Some languages have block conditional statements that include their
statment lists, like this:
| ifstmt | → | if expr then stmtlst [ else stmtlst ] endif |
| stmtlist | → | { statement } |
Is this ambiguous? Why, or why not?
Construct CFGs for:
- A for-each loop that iterates a variable through a list of
expressions. Choose your favorite keywords and syntax.
- Function calls in a language that allows you to omit arguments,
like this: f(a, 10, , n + 1 , , 3).
Construct regular expressions for:
- Identifiers which can contain letters and digits, and may even start with
a digit, but must contain at least one letter.
- C-style strings which must start and end with double quotes, and may
contain double quotes only if preceded by a backwards slash.
Derivation Problem
Regular Expression Problem